● 본 공부와 기록은 유튜버 '노마드 코더 Nomad Coders' 님의 "개발자라면 꼭 알아야할 Hash Table 의 모든 것!"을 기본으로 하였다.
→ https://www.youtube.com/watch?v=HraOg7W3VAM&list=PLBJJM_3zIlbXJYnojluH5W2uPwXmEXAva
☆ HashTables란?
→ HashTable은 Key Value System을 이용해, 자료를 정리한다.
→ Key Value System의 예시로는 사전이 있다.
→ 단어를 찾고 = Key, 해당 단어의 뜻과 설명 = Value가 된다.
☆ HashTables와 Array(배열) 비교해보기
ex) 레스토랑의 메뉴를 배열에 저장한다면, 아래와 같을 것이다.

→ Pizza의 가격이 얼마인지 알고 싶다면, Linear Search(선형 검색)을 하면된다.
→ Linear Search(선형 검색)이란, 각 아이템을 첫번째부터 끝까지 체크하는 방법이다.
→ 이 방법은 시간이 너무 오래걸린다. 메뉴에서 각 메뉴들을 일일이 하나하나 체크해야만 한다.
→ 이럴 때, Hash Tables를 이용한다.
→ 같은 메뉴이지만, Hash Tables로 정리하면 어떻게 될까?

→ 우측과 같은 모습으로 바뀐다.
→ 이 경우, Pizza의 가격을 알고싶다면, pizza가 Key, 가격이 Value로 제공될 것이다.

→ 시간복잡도를 측정해보면 맨 처음 배열로 사용한 방법은 O(N)이라 할 수 있다.
→ Linear Time(선형시간)이고, 배열에 등록된 아이템이 많을수록 찾는 시간 역시 비례한다는 소리다.

→ 그러나 Hash Tables의 시간복잡도를 측정하면, O(1)이다. 즉, Constatnt Time(상수 시간)이다.
→ 이 뜻은 Hash Tables에서 그 어떤 메뉴의 값을 찾더라도, 소요되는 건 딱 1개의 스텝이라는 뜻이다.

→ 아이템을 추가할 때도 마찬가지로 O(1), 삭제할 때도 마찬가지로 O(1)이다.
→ Array와 비교했을 때, 엄청나게 빨라지는 것이다!
☆ Hash Tables를 이용해 더 빠른 배열만들기 ★★★
→ Key와 Value를 저장하지 않고, Value만 저장하고 싶을 때 사용한다.
ex) 좋아하는 국가 리스트가 있다고 가정하자.
→ 만약, 태국이 해당 리스트에 있는지 체크하고 싶다면, 선형 검색을 해야하고 그건 시간이 오래걸리고, 전혀 효율적이지 못하다.

→ 그래서 효율적으로 빠르게 작업하고자 Hash Tables를 사용한다.
→ 국기는 Key가 될 것이고, Value는 True 값으로 지정해주면 된다.


→ 이렇게 하면 태국이 리스트에 있는지 확인하는데, 딱 1번의 스텝만 필요하게 된다.
→ Array처럼 리스트가 존재하지만, 검색 시간복잡도는 O(1)가 되는 것이다.
☆ Hash Tables의 원리
→ Hash Tables에는 array 구조가 존재한다.
→ 모든 Hash Tables 값들은 거기에 존재한다.

→ 그리고 알다시피, Array에서 아이템에 접근하는 방법은 인덱스 번호를 알아야한다.
→ 그렇다면 어떻게 Hash Tables는 내부에 Array와 같은 구조가 있음에도 더 빠를 수 있는 것일까?
→ 그 정답은 Hash Function(해시 함수) 때문이다.

→ Hash Function이 저장하고 싶은 Key를 숫자로 바꿔버린다.
→ 그 숫자가 곧 인덱스가 되는 것이고, 거기에 Value가 저장된다.
→ 조금 더 실감있게 이해하기 위해 레스토랑 메뉴 예제를 살펴보자.
→ 우선 Array 배열이 필요하다.
→ 총 10개의 아이템이 있는 배열을 만들어보자.
→ 여기서 Pizza의 가격을 저장하고 싶다면, 이를 위해 Hash Function을 만든다.
→ 아이템의 이름. 이 경우, 'Pizza'를 가져다가 알파벳 숫자를 세어본다.

→ 이 숫자가 바로 배열 어디에 Pizza 가격을 저장해야할지 알려주는 것이다.

→ 따라서 배열 5번째에 Pizza 가격을 저장하는 것이다.
→ 나중에 Pizza의 가격이 궁금하면 Pizza(=Key)를 가져다가 Hash Function에게 주면, Hash Function은 우리에게 '5'라는 값을 줄 것이고, 리스트 5로 이동하면 그곳에서 Pizza의 값을 찾을 수 있는 것이다.
→ Key를 가져다가 Hash Function에 넣고, 해시 함수가 준 숫자에, Value를 저장하면 된다.
※ Collision
→ Taco의 가격을 저장하고 싶은데, 그 경우 Cake를 Hash Function에 넣는 경우와 값이 같게 나온다.
→ 그러나 4에 이미 Cake의 값이 저장되어 있다고 할 경우, 충돌이 일어나며 이것을 Collision(해시 충돌)이라고 한다.
→ Collision(해시 충돌)은 각기 다른 Key에 대해 Hash Function이 동일한 숫자를 준 경우에 발생한다.
☆ Collision의 대처 방법
➀ 리스트 4번째 공간에 또 다른 Array 배열을 넣는 것이다.
→ 이 배열에 2개의 쌍을 저장하는 것이다.
→ 하나는 Cake와 그 가격, 또 하나는 Taco와 그 가격이다.
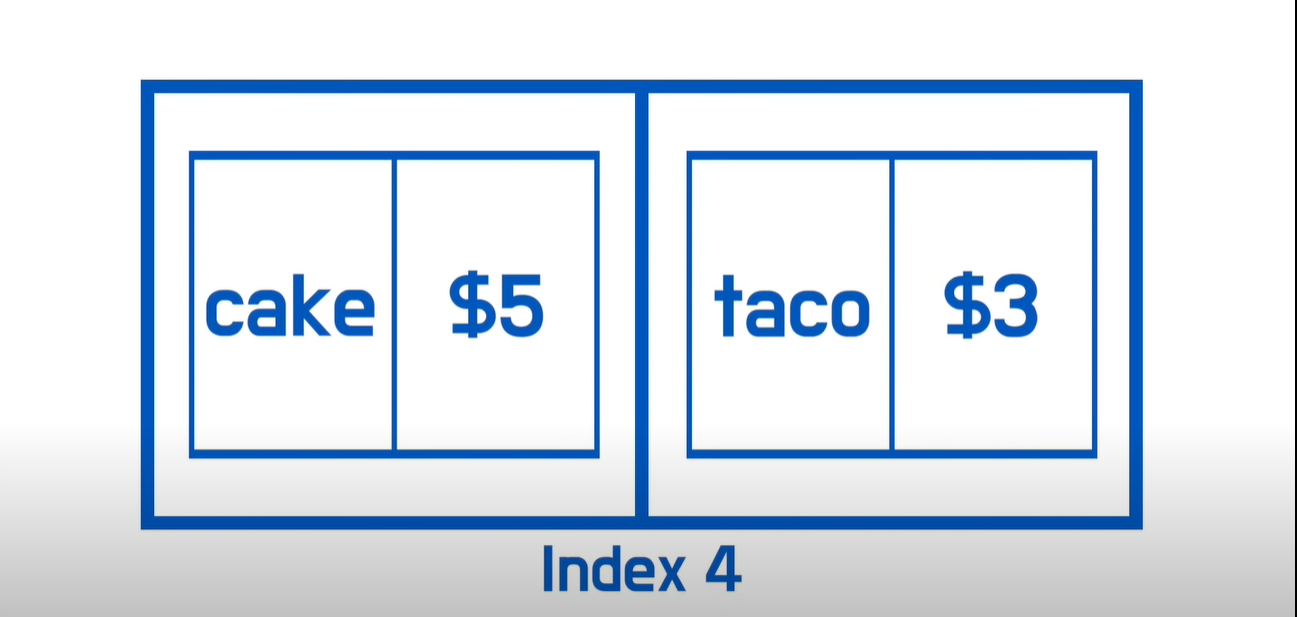
→ 그렇기에 누군가가 Hash Tables에 Cake 가격을 물으면, Cake = key를 해시함수에 넣고 '4'라는 숫자를 줄 것이고, 리스트 4로 이동하여 이곳에서 Cake의 가격을 찾을 때까지 Linear Search 선형검색를 하게 된다.
→ 바로 이러한 이유로 인해 Hash Tables 검색은 언제나 O(1) 상수 시간은 아니다.
→ 왜냐하면 Collision이 있을 수 있고, 이 경우 선형 검색을 해야하기 때문이다.
→ 그러나 평균적으로 Hash Tables의 시간복잡도는 O(1)이다.
→ 거기다 Hash Tables는 이미 여러 프로그램에 상용화되어 있기에 스스로 해시함수를 만드는 등의 노력을 할 필요는 없다.
→ 그러나 그 작동원리를 알아두는 것은 중요하다.
Thanks to Nico
'프로그래밍 > 자료구조 & 알고리즘' 카테고리의 다른 글
| 2021년 8월 5일 - Sorting Algorithm : 버블 정렬 Bubble Sort & 선택 정렬 Selection Sort & 삽입 정렬 Insertion Sort (0) | 2021.08.05 |
|---|---|
| 2021년 8월 4일 - Big O (0) | 2021.08.04 |
| 2021년 8월 3일 - Binary & Linear (0) | 2021.08.03 |
| 2021년 8월 2일 - 배열 Array (0) | 2021.08.02 |
| 2021년 7월 30일 - 알고리즘을 공부해야하는 이유 (0) | 2021.07.30 |




댓글