● 본 공부와 기록은 유튜버 '노마드 코더 Nomad Coders' 님의 "개발자라면 이제는 알아야하는 Big O 설명해드림. 10분컷."을 기본으로 하였다.
→ https://www.youtube.com/watch?v=BEVnxbxBqi8&list=PL7jH19IHhOLMdHvl3KBfFI70r9P0lkJwL&index=5
☆ 알고리즘의 속도를 표현하는 방법
→ "빠르다", "느리다"는 시간으로 표현하지 않는다.
→ "초"나 "분" 단위로도 표현하지 않는다.
→ 같은 알고리즘이라도 컴퓨터마다 속도가 다를 수 있는데, 컴퓨터 하드웨어의 차이가 있기 때문이다.
→ 따라서 알고리즘의 속도는 "완료까지 걸리는 절차의 수"로 결정된다.
→ 그렇기에 같은 작업을 수행하는데 적은 양의 스텝을 필요로 하는 알고리즘이 더 훌륭한 알고리즘이다.
→ 선형검색 Linear Search은 한개씩 검색한다.
→ 따라서 데이터의 개수input size가 N개라면 총 N개의 스텝이 필요하다.
→ O(N)의 시간복잡도를 갖는다고 볼 수 있다.
→ 이러한 컨셉을 Big O 라고 한다.
☆ Big O
→ Big O를 사용하면, 시간복잡도를 읽기 쉽고 빠르게 설명할 수 있다.
→ Big O를 이해하면, 알고리즘 분석을 빠르게 할 수 있고, 언제 무엇을 쓸지 빠르게 파악이 가능하다.
→ 또한, 미래에 어떻게 작동할지 알 수 있으니 자신의 코드를 평가하는 것도 가능하다.
→ 알고리즘의 시간복잡도를 인풋과 연관하여 빠르게 알아낼 수 있다.
★ 상수 시간복잡도 Constant time O(1)

ex) 배열 Array을 인풋으로 사용할 함수가 있다고 가정하자.
→ print(arr[0])은 배열의 첫번째 element를 프린트한다는 뜻이다.
→ 인풋 사이즈가 10이라면, 이 함수는 딱 1번이면 실행이 끝난다.
→ 인풋이 100개라도, 끝내는 건 1번이면 충분하다.
→ 인풋이 얼마나 크든 말든 관계없이 이 함수는 동일한 수의 스텝이 필요하다.
→ 이 함수의 시간복잡도는 상수 시간 Constant time이라고 할 수 있다.
→ 상수 시간Constant time O(1)란, N의 크기와 상관없이 끝내는데 동일한 숫자의 스텝이 필요한 경우다.
→ Big O에서는 아래와 같이 표현한다.

→ 이걸 표현하는 방법은 O(1)이다.
→ 또 다른 예시를 살펴보자.

ex) 첫 번째 아이템을 2번 프린트하는 함수가 있다고 가정하자.
→ 그러면 끝내기 위해서 2개의 스텝이 필요하다.
→ 이때, 시간복잡도는 O(2)가 아니라, 동일하게 O(1)이라고 표현한다.
→ Big O는 함수의 디테일에는 관심이 없고, 큰 원리에만 관심을 둔다.
→ 따라서 이 함수가 프린트를 2번해도, 여전히 O(1)이라고 표현된다.
→ 인풋 사이즈에 상관없이 미리 정해진 숫자에 따라 작동한다는 의미이다.
→ 즉, Big O는 상수constant에는 신경을 쓰지 않는다.
→ 상수 시간 알고리즘 Constant Time Algorithm의 경우, 인풋 사이즈와 상관없이 스텝이 일정한 알고리즘들이다.
→ 당연히 늘 선호되는 알고리즘이다.
→ 그러나 현실적으로 늘 이렇게 만들기는 어렵다.
★ 선형 시간복잡도 Linear time O(N)

ex) 각 아이템을 프린트하는 함수가 있다고 가정하자.
→ 배열의 크기가 10이라면, 10번 프린트하여, 10개의 스텝이 소요된다.
→ 배열의 크기가 100이라면, 100개의 스텝이 필요하다.
→ 이건 선형검색과 비슷하다.
→ 배열의 각각 아이템을 위해 모두 작업해야하며, 배열이 커지면 필요 스텝도 커진다.
→ 이를 Big O로 표현하면 O(N)이다.

→ 마찬가지로 Big O는 상수에는 관심이 없다.
→ 위의 예시처럼 함수를 반복할 때, 이론적으로 O(2N)이 되어야 하지만 여전히 O(N)으로 표현한다.
→ O(2N)이든, O(N)이든 전달하고자 하는 메시지는 동일하기 때문이다.

→ 메시지 : 인풋이 증가하면, 스텝도 선형적으로 증가한다.
★ 2차 시간복잡도Quadratic Time O(n^2)
→ 2차 시간은 중첩 반복 Nested Loops이 있을 때 발생한다.

ex) 배열의 각 아이템에 대하여 루프를 반복 실행하는 함수가 있다고 가정하자.
→ 따라서 시간복잡도는 인풋의 n^2이다.
→ 인풋이 10개라면 완성하는데 100번의 스텝이, 인풋이 20개면 완성하는데 400번의 스텝이 필요하다.
→ 루프 안의 루프에서 함수를 실행하기 때문이다.
→ 이걸 표현하면 O(n^2)이 된다.
→ 따라서 선형시간과 2차 시간과 비교하면

→ 선형 시간복잡도가 더 효율적인 것으로 선호된다.
★ 로그 시간복잡도 Logarithmic Time O(log N)
→ 이진검색 알고리즘 Binary Search Algorithm을 설명할 때 쓰인다.
→ 이진검색에서는 인풋 사이즈가 두 배가 되어도, 스텝은 딱 +1 밖에 증가하지 않았다.
→ 이진검색에서는 각 프로세스의 스텝을 절반으로 나눠서 실행하기 때문이다.
→ 이걸 표현하면 O(log N)이 된다.


→ 로그 logarithm는 지수 exponent의 정 반대이다.
→ 위의 풀이는 이진검색을 연상케 만든다.
→ 이진검색에서는 인풋을 매 스텝마다 일단 반으로 나누고 시작한다.
→ 그렇기 때문에 인풋이 2배로 커져도 한 번만 더 나누면 되기에, 검색을 하기 위한 스텝은 +1만 증가하는 것이다.
→ 따라서 이진검색 Binary Search의 시간복잡도는 O(log n)인 것이다.
→ 참고로 Big O에선 log의 밑base을 적지않는다.
→ 위의 경우, log32의 밑base은 2인데, Big O의 특성상 밑base인 2가 생략된다.


→ 선형시간 Linear Time보다는 빠르고

→ 상수 시간 Constant Time 보다는 느리다.
→ 여기엔 트레이드 오프 Trade Off가 존재한다.
→ 이진검색은 정렬되지 않은 배열엔 사용할 수 없다.
☆ 정리
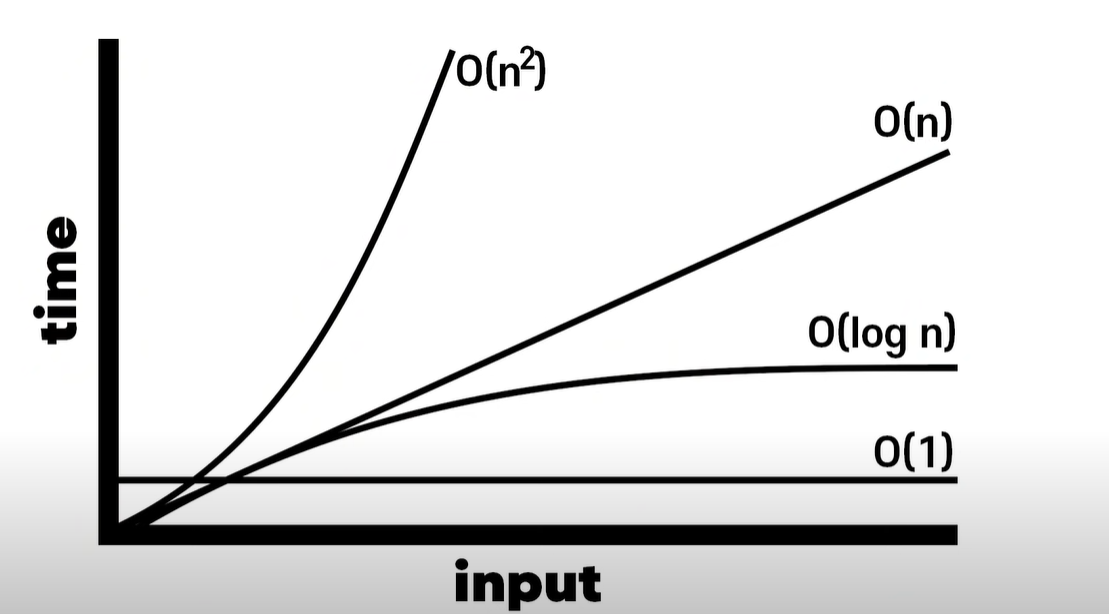
→ 가장 선호되는 것은 상수 시간이다.
→ 인풋이 늘어나도 작업에 필요한 스텝이 변하지 않는다.
→ 그 다음엔 로그 시간, 선형 시간, 2차 시간 순서대로 좋다.
→ 지수 시간이나 2차 시간으로 가면 꽤 복잡해지기 시작한다.
→ 그러나 Big O가 전체를 반영하지 못하는 경우가 있다.
→ 다음에는 동일한 시간복잡도를 가지고 있으나(O(N)), 전혀 다르게 작동하는 2개의 알고리즘을 살펴보자.
'프로그래밍 > 자료구조 & 알고리즘' 카테고리의 다른 글
| 2021년 8월 20일 - Stack & Que (0) | 2021.08.20 |
|---|---|
| 2021년 8월 5일 - Sorting Algorithm : 버블 정렬 Bubble Sort & 선택 정렬 Selection Sort & 삽입 정렬 Insertion Sort (0) | 2021.08.05 |
| 2021년 8월 3일 - Binary & Linear (0) | 2021.08.03 |
| 2021년 8월 2일 - 배열 Array (0) | 2021.08.02 |
| 2021년 7월 30일 - 알고리즘을 공부해야하는 이유 (0) | 2021.07.30 |




댓글