◎ 본글은 아래의 김강민 강사님의 강의를 필기한 내용입니다.
https://jonhyuk0922.tistory.com/115
[SQL] SQLD 공부방법 & 합격후기 (꿀팁 많음)
안녕하세요~! 27년차 진로탐색꾼 조녁입니다! 이번에는 제가 지난 3월 20일에 응시했던 SQLD 자격증 시험 공부방법 / 시험보며 느낀 점 / 합격 후기를 남기려합니다. 참고로 저도 전공자는 아니고,
jonhyuk0922.tistory.com
윈도우 함수 (Problem Solving)
1. Rows between VS Range between
→ Range는 범위로 판단하기에 같은 값이 나올 확률이 있다.

2. Rank VS Dense_Rank
→ Rank : 중복 등수가 존재할 경우 후순위 등수를 건너뛴다 - 1, 1, 3, 4
→ Dense_Rank : 중복 등수가 존재해도 건너뛰지 않는다. - 1, 1, 2, 3
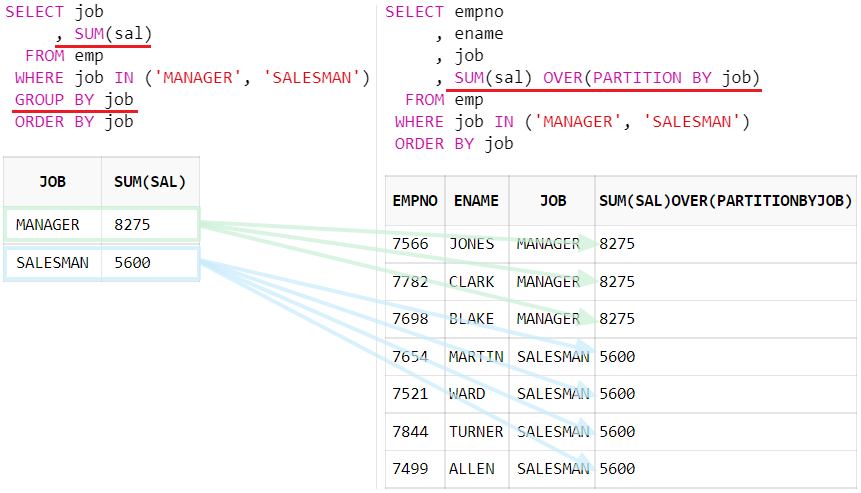
3. Partition by VS Order by
→ Partition by : 그룹 내 순위 및 그룹 별 집계를 구할 때 유용하게 사용할 수 있다. GROUP BY 절을 사용하지 않고, 조회된 각 행에 그룹으로 집계된 값을 표시할 때 OVER 절과 함께 PARTITION BY 절을 사용하면 된다.
계층형 질의
1. 이론
1) Prior 자식데이터 = 부모데이터
2) 부모에서 자식으로 가면 순방향
2. 쿼리작성

절차형 PL/SQL
1. Exception → 생략 가능
2. Procedure VS Trigger VS Userdefined Function
→ Procedure : 반드시 값이 안나옴
→ Trigger : Commit & Rollback 불가
→ Userdefined Function : 반드시 값이 나옴
데이터모델링
1. 복잡한 현실의 업무 → 데이터모델화
2. 관계형 DB의 지도를 그리는 방법
엔터티
= 업무상 관리하고자 하는 대상
ex) 병원에서 환자를 관리할 때 엔터티는? 관리대상이 되는 환자
1. 특징
1) 인스턴스 2개 이상 가져야 함
2) 관계 1개 이상 가져야 함
3) 업무에서 사용해야 하고 업무 프로세스에 이용되어야 함
2. 분류 (유개사 기중행)
1) 유형 엔터티
2) 개념 엔터티
3) 사건 엔터티
4) 기본 엔터티
5) 중심 엔터티
6) 행위 엔터티
속성
1. 특징
1) 관리하고자 하는 인스턴스의 특성, 특징들을 속성이라 함
2) 속성은 인스턴스들의 집합
2. 분류
1) 기본 속성
→ 사원이름, 직책이름, 고용일자 등이 가장 일반적인 속성이다.

2) 설계 속성
→ 업무상 필요한 데이터 외에 데이터 모델링을 위해 업무를 규칙화하기 위해 속성을 새로 만들거나 변형하여 정의하는 속성이다.

3) 파생 속성
→ 다른 속성에 영향을 받아 발생하는 속성으로, 계산된 값들이 여기에 해당한다. 다른 속성에 영향을 받으므로, 영향받는 속성을 알아두어야 하는 등 유의할 점이 많아서 가급적 적게 정의하는 게 좋다.

도메인
→ 데이터 유형, 크기, 제약 조건, 값의 범위, 어떤 값을 가져야하는가 등
ex) Check, Primary key 등등
관계
1. IE 표기법
→ 네모 낳게 그린다.
→ 식별자(PK)는 위에 올린다.
→ 나머지 일반 속성들을 밑에 놓는다.
→ 까마귀 발
→ 필수관계 : 짝대기
→ 선택관계 : 원과 짝대기
2. Barker 표기법
→ 소프트셀이라고 모서리가 둥근 박스에 쓴다.
→ 식별자는 # 라고 표기
→ 나머지는 O 형태
→ 까마귀 발
→ 점선과 실선으로 표시

식별자
1. 식별자 비식별자 관계(ERD) 표기법
1) 점선 : 비식별자
2) 실선 : 식별자
2. 주식별자 특징 (유최불존)
1) 유일성
→ 해당 인스턴스를 유일하게 구분하는 속성
2) 최소성
→ 여러가지 속성을 묶어서 또 식별이 가능한데 이게 최소여야 함
3) 불변성
→ 한번 만들어 놓으면 바뀌지 않음
4) 존재성
→ Not Null 조건
→ 이 모든 것을 만족하면 '후보키' → 여기서 선별된 것이 기본키/대체키
식별자 관계, 비식별자 관계

ERD 서술규칙
1. 시선은 좌상 → 우하
2. 관계명은 반드시 표기하지 않아도 괜찮다.
3. UML → 객체지향에서만 쓰인다.
성능 데이터 모델링
1. 아키텍쳐 모델
→ 파티션, 테이블 등 데이터베이스의 구조를 계속 바꾸는 것
2. SQL 명령문을 수리
→ 조인 수행 원리
→ 옵티마이저
→ 실행계획
정규화
1. 정규화 방법
1) 1차 : 원자성 확보
2) 2차 : 부분함수 종속 제거
3) 3차 : 2행함수 종속 제거
4) BCNF : 후보키가 상속하는 거 제거
2. 이상현상
1) 삽입이상
2) 삭제이상
3) 갱신이상
3. 성능
1) Select절에서는 조인으로 인해 성능이 느려질 수 있음
2) Insert, Update의 경우 성능 개선 - 테이블이 작아지기 때문
반정규화
1. 특징 (대범한 통조림)
1) 데이터 무결성을 해침
2) 대량 범위
3) 범위 처리
4) 통계 처리 여부
2. 다른 방법 고려
1) 응용 시스템 변경
2) 클러스터링/ 인덱스
3) 뷰
3. 반정규화 방법 (테속관)
1) 테이블 반정규화
(1) 병합
- 1:1 & 1:M & 슈퍼/서브
(2) 분할 (부분 통증)
- 부분 테이블
- 통계 테이블
- 중복 테이블
2) 속성 반정규화
(1) 파생
(2) 오류
(3) 이력 컬럼
(4) PK → 속성
(5) 중복속성
3) 관계 반정규화
(1) 중복 관계 추가
데이터에 따른 성능
1. row migration

2. row chaining

3. 파티셔닝
→ 위의 두개를 해결하기 위한 방안
1) List Partitioning
2) range Partitioning
→ 관리가 쉬움
→ 가장 많이 쓰인다
3) Hash Partitioning
→ 관리가 어려움
슈퍼/서브타입
1. 용량별로 처리가 가능
1) 작은 경우 : one to one - 트랜잭션이 개별로 들어가는 경우
2) 클 경우 : 트랜잭션 유형으로 분류됨
2. 트랜잭션 유형에 따라서 처리가 가능
1) Plus type : 공통/차이점에 따라
2) Single Type : 전체 통합

분산 데이터베이스
1. 특징
1) 데이터 무결성을 해칠 수 있다 - 반정규화와 비슷하다
2) 투명성
조인 수행원리
1. NL 조인
1) 랜덤 액세스
2) 대용량 솔트 작업시 유리
2. Sort merge 조인
1) 조인키를 기준으로 정렬
2) 등가 비등가 조인
3. Hash 조인
1) 등가 조인 Only
2) 선행 Table 작다
3) Hash 처리를 하기에 별도의 저장공간이 필요하다
옵티마이저
1. CBO (Cost Based Optimizer)
→ 경로를 짜봤을 때 가장 저렴하고 경제적인 것
2. RBO (Rule Based Optimizer)
→ 규칙에 따라서
인덱스
1. 사용되지 않는 경우
1) 부정형
2) Like
3) 묵시적 형변환
2. 인덱스 사용시 성능 감소
→ 목차를 달아놨는데 책에 영향을 주는 일이 벌어지면 목차를 계속 바꾸어줘야 함
1) insert
2) update
3) delete
실행계획
1. 실행순서
1) 들여쓰기
→ 더 많이 들여쓰기 되어 있을수록 빠르게 작동
2) 같은 들여쓰기일 경우, 위에 있는 게 먼저 실행
3) 뭉탱이로 움직임

Pivot / Unpivot
1. Pivot
= 행으로 나열되어 있는 데이터를 열로 나열하여 보기 쉽게 가공하는 것
2. Unpivot
= 열을 값으로 변환하여 레코드에 기록
'자격증 > SQLD' 카테고리의 다른 글
| 2022년 2월 17일 - SQLD 핵심 개념 정리 필기 (1) : SELECT 문장 ~ 트랜잭션 관리 언어(TCL) (0) | 2022.02.17 |
|---|

댓글